Алгоритм прогнозирования числовых значений. Основное уравнение линейной регрессии имеет вид:
y = w_0 + w_1 \cdot x_1 + w_2 \cdot x_2
Если коэффициенты и переменные свернуть в векторы:
\hat{y} = \mathbf{w}^\top \mathbf{x} + b
Уравнение описывает линию или плоскость (или гиперплоскость, если измерений больше 3) – описывающую исходную зависимость. Позволяет дать общее описание данных и спрогнозировать численное значение данных для ранее неизвестных входных значений.
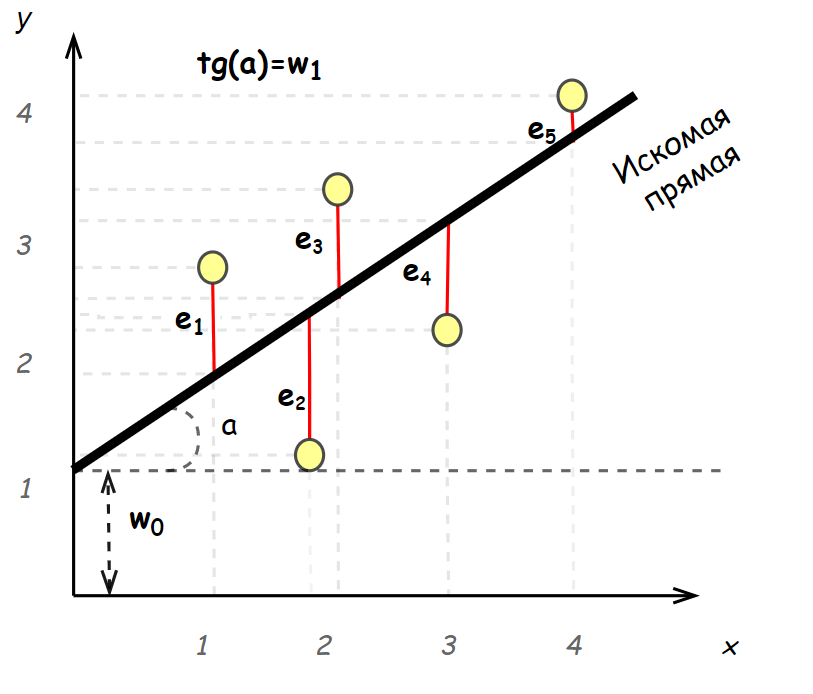
Метод наименьших квадратов – механизм нахождения коэффициентов w линейной регрессии. В случае плоскости, алгоритм стремится провести прямую, проходящую как можно ближе к точкам данных – чтобы сумма всех расстояний от прямой до точек в сумме было минимальным. Квадрат (вторая степень) используется для того, чтобы компенсировать отрицательные значения расстояния, возникающие для точек, находящихся ниже прямой.
Метрики линейной регрессии
mae – средняя абсолютная ошибка:
mae = \sum_{i=1}^{n} \frac {(y_i - y) }{n}
mse – среднеквадратичная ошибка:
mse = \sum_{i=1}^{n} \frac {(y_i - y)^2}{n}
R^2 – коэффициент детерминации
R^2 = 1 - \frac {mse}{mse(mean)} - показывает, какую долю дисперсии объясняет модель
Есть и другие метрики, но их выбор зависит от данных. Для некоторых ситуаций (сильный разброс данных) могут быть
удобны другие метрики, так как они будут более интерпретируемыми.
Суть подгонки коэффициентов линейной регрессии – это минимизация среднеквадратичной ошибки.
Основные методы решения задачи регрессии
Аналитический – с помощью матриц
\mathbf{w} = \left( \mathbf{X}^\top \mathbf{X} \right)^{-1} \mathbf{X}^\top \mathbf{y}
w = (X^TX)^(-1)X^T*y – получаем нужный нам вектор весов. Этот алгоритм очень затратный (сложность получения обратной матрицы – О(N^3)). Если есть мультиколлинеарность – то матрица окажется вырожденной, и взять обратную матрицу не получится.
Градиентный спуск – численный метод оптимизации весов
Сначала веса берутся случайные, затем они применяются и считается MSE.
Затем берется градиент от MSE и делается шаг в направлении антиградиента по формуле:
\theta := \theta - \alpha \cdot \nabla_\theta \mathcal{L}(\theta)
θ := θ − α ∇L(θ)
Помним, что градиент показывает направление возрастания функции, поэтому мы берем его со знаком минус.
Реализация линейной регрессии с помощью Scikit Learn
На примере данных California Housing реализована стандартная линейная регрессия, линейная регрессия с регуляризацией (L1, L2, ElascicNet), линейная регрессия с добавлением полиномиальных признаков.
from sklearn.linear_model import LinearRegression, Ridge, Lasso, ElasticNet
from sklearn.datasets import fetch_california_housing
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, root_mean_squared_error
# Download and view data
housing = fetch_california_housing(as_frame=True) # Возвращает данные в формате pandas df
print(housing.data.shape, housing.target.shape)
print(housing.feature_names)
data = housing.data
target = housing.target
# Learn Linear Regression
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2)
lr = LinearRegression() # Рассмотреть применение fit_intercept=True/False - определяет, пройдет ли плоскость через начало координат
# Заодно посмотреть, в чем суть и как меняется расположение данных на плоскости после центрирования (StandardScaler или другого)
# должны стать ближе к центру плоcкости (к 0).
lr.fit(X_train, y_train)
y_pred = lr.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
rmse = root_mean_squared_error(y_test, y_pred)
print(f"COEF: {lr.coef_}")
print(f"MSE: {mse:.5f} - Linear Regression")
print(f"RMSE: {rmse:.5f} - Linear Regression")
print()
# Learning Linear Regression with L1/L2 regularization
# L2 regularization - Ridge
ridge = Ridge(alpha=100)
ridge.fit(X_train, y_train)
y_pred = ridge.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
rmse = root_mean_squared_error(y_test, y_pred)
print(f"COEF: {ridge.coef_}")
print(f"MSE: {mse:.5f} - Ridge")
print(f"RMSE: {rmse:.5f} - Ridge")
print()
# L1 regularization - Lasso
lasso = Lasso(alpha=1.0)
lasso.fit(X_train, y_train)
y_pred = lasso.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
rmse = root_mean_squared_error(y_test, y_pred)
print(f"COEF: {lasso.coef_}")
print(f"MSE: {mse:.5f} - Lasso")
print(f"RMSE: {rmse:.5f} - Lasso")
print()
# L1/L2 elasticnet regularization
elastic = ElasticNet(alpha=100, l1_ratio=1.0)
elastic.fit(X_train, y_train)
y_pred = elastic.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
rmse = root_mean_squared_error(y_test, y_pred)
print(f"COEF: {elastic.coef_}")
print(f"MSE: {mse:.5f} - ElasticNet")
print(f"RMSE: {rmse:.5f} - ElasticNet")
print()
# Добавление полиномиальности (признаки 2 и более степени)
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline # Удобно применить полиномиальные признаки через пайплайн
degree = 3
model = make_pipeline(PolynomialFeatures(degree), LinearRegression())
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
rmse = root_mean_squared_error(y_test, y_pred)
print(f"COEF: {lr.coef_} - PolynomialFeatures")
print(f"MSE: {mse:.5f} - Linear Regression with PolynomialFeatures")
print(f"RMSE: {rmse:.5f} - Linear Regression with PolynomialFeatures")