Выбросы – это значения признака, заметно отличающиеся от основной массы значений. Примеры выбросов: возраст человека более 150 лет, рост человека более 3м, скорость автомобиля более 500 км в час и т.д.
При работе с выбросами важно учитывать контекст задачи. Наличие выбросов может указывать на ошибки измерений при сборе признаков или вводе данных, или же выбросы могут являться аномалиями, явно указывающими на важные нюансы бизнес-процесса.
Существует много способов обнаружения выбросов и несколько подходов по работе с ними (удаление, преобразование и т.д.).
Основные способы выявления выбросов
Pandas – train_data.describe().T
Применение метода .describe() в транспонированной форме к табличным числовым данным позволяет заметить наличие выбросов. Например: в статистической сводке среднее значение будет заметно отличаться от медианы. Также может броситься в глаза аномальное значение минимума или максимума для конкретного признака.
Визуализация значений признака
Для нужного признака строится диаграмма box-plot или scatter-plot, позволяющие сразу же идентифицировать наличие выбросов.
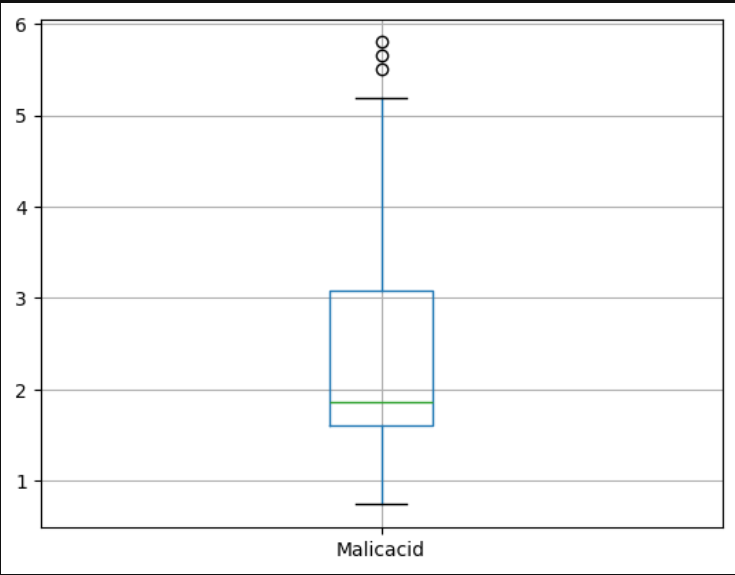
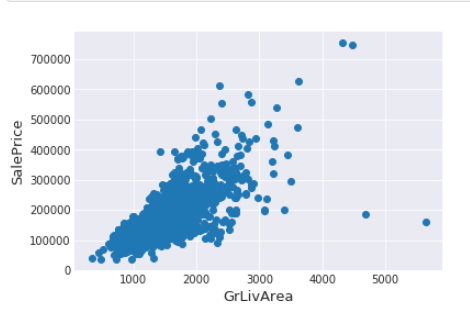
Метод межквартильного размаха (IQR)
Выбросы определяются как значения, выходящие за пределы Q1 – 1.5xIQR и Q3 + 1.5xIQR, где Q1 – первый квартиль, Q3 – третий квартиль, IQR – численная разница между 1 и 3 квартилями. Выброс может быть как выше, так и ниже указанных значений.
Для получения датафрейма, содержащего выбросы, и очищенного от выбросов датафрейма можно воспользоваться кодом:
def get_outliers(df):
# Выберем только числовые столбцы - на случай, если есть и другие типы данных
numeric_cols = df.select_dtypes(include=np.number).columns
# Создадим общую маску для всех выбросов. Она решает проблему дублирования строк с выбросами, ведь в одной строке в разных столбцах могут встретиться 2 и более выбросов
outlier_mask = pd.Series(False, index=df.index)
# Проходим циклом по числовым столбцам датафрейма
for col in numeric_cols:
Q1 = df[col].quantile(0.25)
Q3 = df[col].quantile(0.75)
IQR = Q3 - Q1
lower_limit = Q1 - 1.5 * IQR
high_limit = Q3 + 1.5 * IQR
# Маска для текущего столбца
current_mask = (df[col] < lower_limit) | (df[col] > high_limit)
# Условие "или" обеспечивает перезапись значений в outlier_mask на True для уже проверенных строк, исключая тем самым дублирование строк в итоговой маске.
outlier_mask = outlier_mask | current_mask
# Возвращаем датафрейм, содержащий только строки с выбросами
return df[outlier_mask] # Для получения датафрейма с удаленными строками с выбросами надо инвертировать маску df[~outlier_mask]
X_without_outliers = get_outliers(X)
X_without_outliersZ-score
Z-оценка показывает, на сколько стандартных отклонений значение признака отличается от среднего. Как правило, выбросами считаются значения признака, отклоняющиеся от среднего значения более, чем на 3 стандартных отклонения.
Методы на основе плотности
С помощью алгоритма кластеризации (например: DBSCAN) можно идентифицировать точки, не принадлежащие кластерам высокой плотности. Их и считают выбросами.
ML для выявления аномалий
Для обнаружения аномальных значений используются готовые алгоритмы IsolationForest, One Class SVM.
Локальный фактор выброса (LOF, Local Outlier Factor)
В отличие от глобальных методов, которые оценивают выбросы, основываясь на общем распределении данных, локальный фактор выброса оценивает выбросы, сравнивая плотность данных в локальном окружении.
В основе метода лежит алгоритм k-means. Значение локального фактора выброса рассчитывается по специальной формуле.
Существует реализация этого метода в sclearn: from sklearn.neighbors import LocalOutlierFactor
Эвристические методы
Выбросы определяются с опорой на бизнес-логику задачи.
Обработка выбросов
Удаление выбросов – полезно, если НЕМНОГОЧИСЛЕННЫЕ выбросы являются результатом ошибок измерения или ввода данных. Стоит дважды подумать перед удалением выбросов, так как это потеря важной информации о данных.
Удалять выбросы из тестовой/валидационной выборке нельзя. Если в ней есть выброс, действительно являющийся ошибкой ввода, стоит заменить его медианным значением.
Замена выбросов – в некоторых случаях выбросы удобнее заменить на среднее или медиану по данному признаку. Применяется также обрезка выбросов по IQR. То есть выбросам присваивается значение ближайшего к ним значения IQR +/- 1.5*IQR.
Ограничение (Capping/Clipping) - определение верхних и/или нижних границ (например, квантили 5% и 95% или границы по IQR-методу) и замена всех значений за пределами этих границ на сами границы. Это более безопасно, чем удаление, так как сохраняет объем данных.
Трансформация данных признака – например, логарифмирование, чтобы снизить влияние выбросов.