При первичном знакомстве с табличными данными важно выполнить ряд шагов, чтобы исключить распространенных ошибок.
Разбиение на train/test/val выборки
Выполняется самым первым шагом, чтобы исключить проблему утечки данных при дальнейших преобразованиях. Соревновательные данные на Kaggle обычно уже разбиты на тестовые и тренировочные.
Данные разбиваются на три неравных датасета, используемых для разных целей.
- train – для обучения модели
- val – для отладки гиперпараметров модели
- test – для финальной проверки – эти данные используются только один раз в самом конце работы для финального тестирования модели.
Почему это важно?
Если провести любой анализ (например, вычислить среднее, медиану или стандартное отклонение) по полному набору данных, а затем использовать эти статистики для предобработки/нормализации, информация о тестовых данных “просочится” в обучающую выборку. Это приведет к чрезмерно оптимистичной оценке качества модели.
Пример разбиения
from sklearn.model_selection import train_test_split
# 1. Разделение на обучение + валидация (70-80%) и тест (20-30%)
train_val, test = train_test_split(df, test_size=0.2, random_state=42)
# 2. (Опционально) Разделение на обучение и валидацию
train, validation = train_test_split(train_val, test_size=0.25, random_state=42)
Важно, что при выполнении преобразований в наборе train, два других набора данных должны быть преобразованы аналогичным образом. Но есть нюансы, описанные в соответствующих разделах поста. Для обеспечения идентичности преобразований в наборах данных рекомендуется использовать Sklearn Pipeline.
Создание копий данных
Работа с созданными выборками подразумевает их преобразование и создание новых признаков. Рекомендуется выполнять эти операции с копиями, сохраняя исходные наборы отдельно.
train_eda = train.copy()
test_eda = test.copy()
val_eda = val.copy()
Изучение взаимосвязи признаков – корреляция
До преобразования всех категориальных признаков в числовой формат, заполнения пропусков, удаления/обработки выбросов, трансформации данных стоит проверить все данные на корреляцию. Правила работы с корреляционной матрицей.
На этом этапе не спешить удалять мультиколлинеарные признаки. Будет еще одна проба на корреляции – после обработки данных.
Пример кода:
# Построение корреляционной матрицы для изучения числовых признаков
# для начала отфильтруем только числовые признаки
numeric_data = train_data.select_dtypes(include=['number'])
cormat = numeric_data.corr()
plt.subplots(figsize=(12, 9))
sns.heatmap(cormat, vmax=0.9, square=True)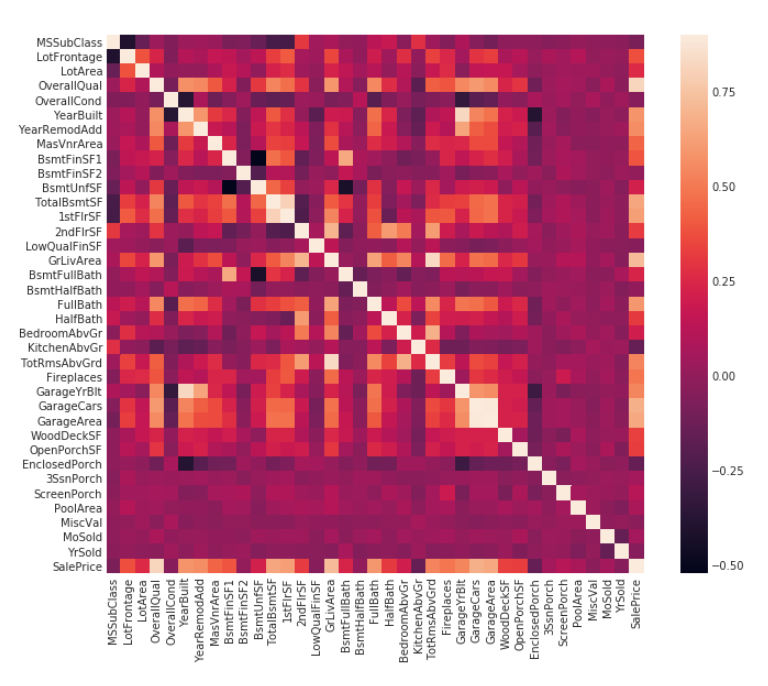
Идентификация целевой переменной
Необходимо отделить таргет от остальных признаков, чтобы случайно не использовать ее как признак. Важно сделать это и в тестовых выборках.
X_train_eda = train_eda.drop('Target', axis=1)
y_train_eda = train_eda['Target']
X_test_eda = test_eda.drop('Target', axis=1)
y_test_eda = test_eda['Target']
X_val_eda = val_eda.drop('Target', axis=1)
y_val_eda = val_eda['Target']
EDA – исследовательский анализ данных
Важное предисловие
Некоторые крупные специалисты по данным отмечают, что не слишком погружаются в EDA, а просто сразу проводят предобработку признаков и в процессе просматривают признаки глазами. Это экономит много времени, однако, может заметно снизить качество моделей.
Обычно все исследовательские операции выполняются с тренировочными данными. Но следует также исследовать и целевую переменную (тип данных, статистики, распределение и смещения, консистентность и отсутствие ошибок.
Найти признаки времени – если есть
Основная статья о работе с признаком времени + идеи по работе с признаком времени.
Получение основных статистик
X_train_eda.info() – получение информации о количестве данных и их типах. Обратить внимание на пропуски, типы данных.
X_train_eda.describe().T – получение информации о числовых данных (статистики). Обратить внимание на минимальные и максимальные значения, соотношение между медианой и средним.
Проверка типов данных
Убедиться, что для каждого признака данные представлены правильным типом данных. Например, числа – в числовом, текст – в стоковом, время – в datetime или timestamp и т.д.
Основной способ проверки типов данных: train_eda.info(). Также есть train_eda.dtypes.
# Посмотреть все признаки и их типы
train_eda.info()
# Посмотреть только типы данных для всех признаков
train_eda.dtypes
# Посмотреть один признак
train_eda['feature_1'].dtypes
Если обнаружены несоответствия в типах, выполнить преобразование. И не забыть сделать это в тестовых данных. Например:
# Преобразование признака в тип int
train_eda['feature_1'] = train_eda['feature_1'].astype('int')
# Преобразование признака в timestamp
train_data['datetime'] = pd.to_datetime(train_data['datetime'])
Проверка распределений числовых признаков
Необходимо узнать, насколько близки к нормальным распределения всех числовых признаков. Если признак распределен с отклонениями, имеет “хвосты” и искажения от нормального, стоит подумать о преобразовании.
Наиболее удачное преобразование при отклонении данных от нормальных – логарифмирование.
Проверка консистентности данных
Для проверки необходимо погрузиться в суть признаков и найти внутренние взаимосвязи, логику и т.д. Проверяется согласованность в признаках, названиях, логике данных. Основная статья.
Например, необходимо убедиться, что в данных используются правильные/однородные единицы измерения.
Значения признаков не должны содержать разных обозначений для одного и того же. Например, usa, U.S.A. и USA означают обычно одно и то же – Соединенные Штаты Америки. Необходимо привести это обозначение к одному виду, если в признаке встречаются разные обозначения. И т.д.
В значениях не должно быть ошибок ввода и т.д.
Основные методы проверки:
# Просмотр всех возможных значений для столбца и выявление странностей
X_train_eda['feature'].value_counts()
# Фильтрация по условию. Например, сравниваем возраст и рабочий стаж. Первое всегда должно быть больше второго. Фильтр покажет нелепые ситуации, когда возраст сотрудника меньше его рабочего стажа.
X_train_eda[X_train_eda['Age'] <= X_train_eda['Experience']]
# Использование .duplicated() в Pandas для поиска полных или частичных дубликатов
X_train_eda.duplicated()
Удаление ненужных индексов
Если в данных есть идентификаторы (ID) или ненужные индексные столбцы, их нужно сразу удалить или перенести в индекс DataFrame. Эти столбцы не являются предикторами, но могут быть ошибочно использованы.
Проверка на пропуски
Основная статья о работе с пропусками.
X_train_eda.info() – уже содержит данные о пропусках.
X_train_eda.isna().sum().sort_values(ascending=False).head(10) – просмотр пропусков по столбцам.
На этом этапе необходимо выбрать стратегию заполнения пропусков или принять решение об удалении части данных с пропусками.
- Для числовых признаков пропуски можно заполнить медианой, средним, модой и т.д.
- Для категориальных признаков пропуски часто заполняют модой.
- Зачастую пропуски означают простое отсутствие данных о признаке – в этом случае их можно заменить значением none или no.
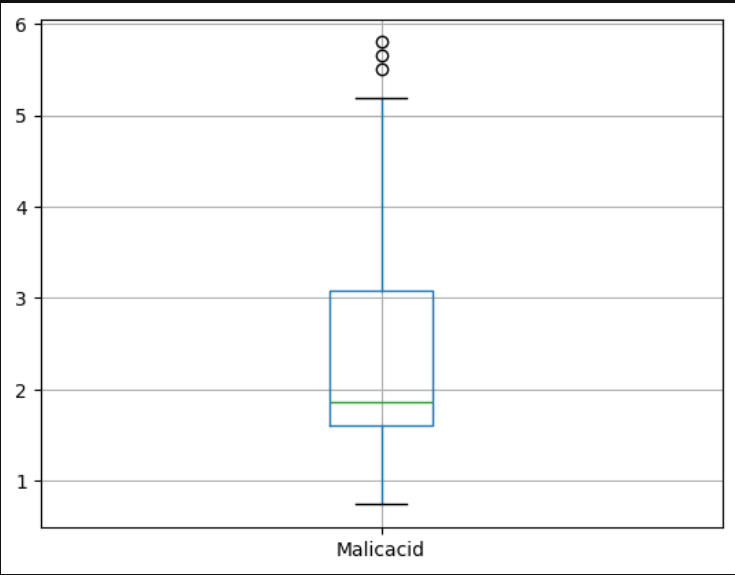
Проверка на выбросы для числовых значений
Основная статья о работе с выбросами.
Наиболее прямой и простой способ найти выбросы – построить boxplot или scatterplot.
Построение boxplot для всех признаков в датафрейме с помощью Pandas:
for column in X.columns:
X.boxplot(column=column) # строим боксплот для каждой колонки данных
plt.show()Результат
Построение scatterplot средствами библиотеки Matplotlib
fig, ax = plt.subplots()
ax.scatter(x = train['GrLivArea'], y = train['SalePrice'])
plt.ylabel('SalePrice', fontsize=13)
plt.xlabel('GrLivArea', fontsize=13)
plt.show()Результат
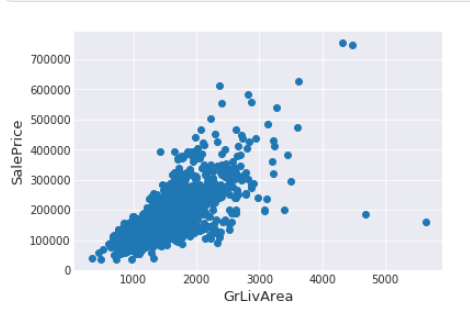
Удаление немногочисленных выбросов с помощью фильтрации – пример:
train = train.drop(train[(train['GrLivArea']>4000) & (train['SalePrice']<300000)].index)Изучение целевой переменной
Если она числовая (в задачах регрессии):
- изучить распределение и сделать выводы о скошенности, асимметрии и эксцессе
- оценить на выбросы
Если она категориальная (задача классификации):
- оценить баланс классов
Кодирование категориальных признаков
Основная статья о кодировании признаков.
Масштабирование и трансформация признаков
Основная статья о масштабировании и нормализации признаков. Крайне важно при этом избежать утечки данных. То есть преобразование тестовых и валидационных данных должно быть обучено на тестовых данных (fit_transform – для train, и только transform для test/val).
Создание новых признаков
Например, с помощью Dummy переменных.
Повторное изучение взаимосвязи признаков
После преобразования всех категориальных признаков в числовой формат, заполнения пропусков, удаления/обработки выбросов, трансформации данных стоит снова проверить все данные на корреляцию.
Именно на этом этапе следует принимать решение об удалении или объединении мультиколлинеарных признаков, или применении модели с регуляризацией.
Здесь же принимается решение о выборе модели. Высокая корреляция подтверждает, что линейные модели будут работать хорошо.
Признаки, хорошо коррелирующие с таргетом – это важнейшие для модели признаки. Однако, корреляция не должна быть равна 1. В идеале – 0.8-0.9.
Признаки из train данных, коррелирующие между собой – плохо. Необходимо либо объединить их в один, или удалить один из них. Либо выполнить другие манипуляции, чтобы убрать избыточную информацию (например, применить преобразование PCA – метод главных компонент). Не забыть выполнить эти же манипуляции с признаками в тестовых данных.